The Medallion Architecture was designed for messy data lakes. Your GenAI knowledge base probably isn't one.
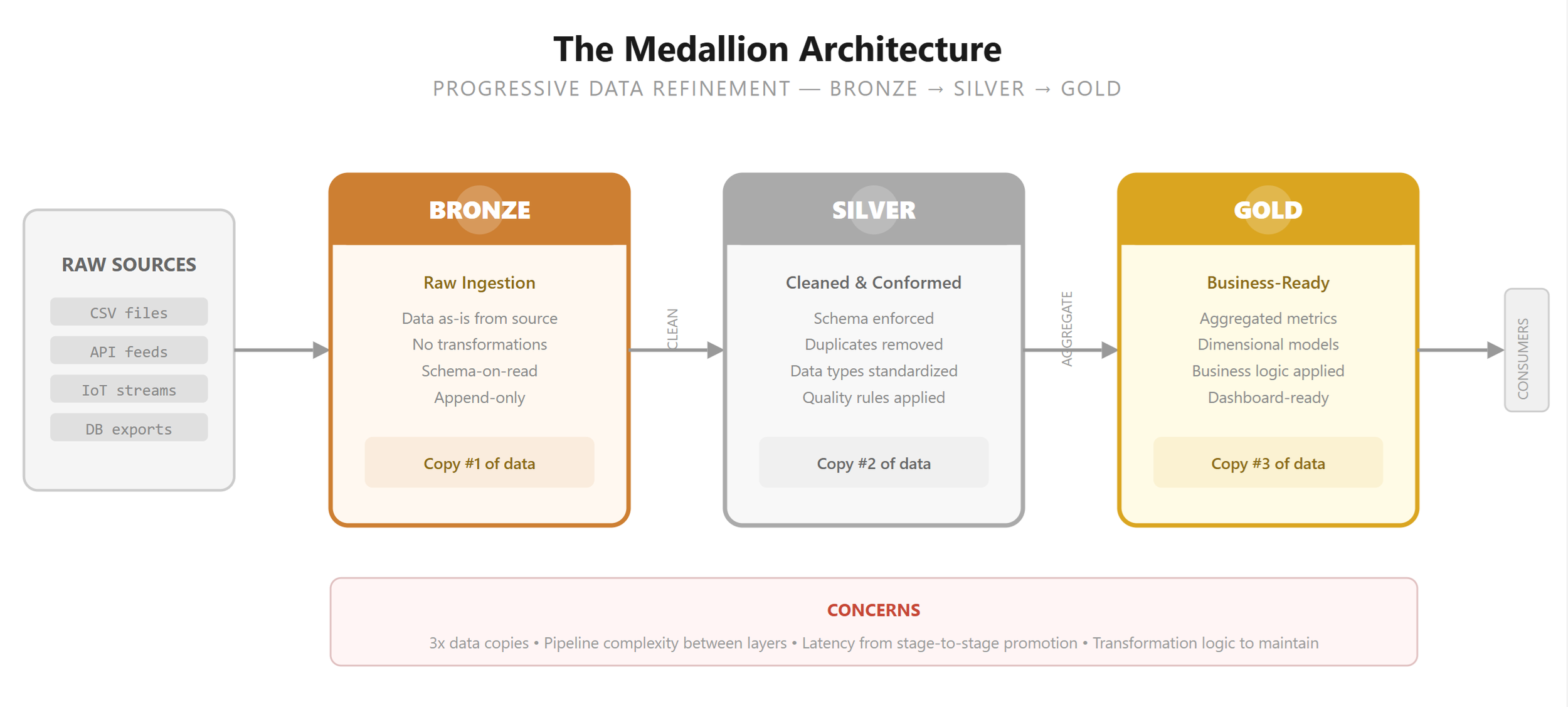
If you have spent any time around data engineering in the past five years, you have encountered the Medallion Architecture — bronze, silver, gold. Raw data lands in bronze. Cleaned and conformed data moves to silver. Business-ready, aggregated data arrives in gold. The pattern emerged from the data lakehouse movement, and for good reason: when your source data is messy, inconsistent, and arrives in unpredictable formats, you need a pipeline that progressively refines it into something useful.
The pattern solved a real problem. Data lakes were swamps. Data scientists spent 80% of their time cleaning data and 20% analyzing it. The Medallion Architecture formalized the cleaning process into discrete, auditable stages. It was the right answer for that era.
But we are no longer in that era.
• • •
The GenAI Data Problem Is Different
I have been building what we call the Digital Brain — a knowledge repository that serves as the core of our GenAI applications. It contains hundreds of thousands of documents: Oracle methodologies, delivery accelerators, configuration patterns, best practices, architecture guides. These documents are fed into vector stores, chunked, embedded, and retrieved by AI agents via RAG pipelines.
Here is what is different about this data compared to what the Medallion Architecture was designed for:
It is unstructured, not tabular. We are ingesting PDFs, Word documents, presentations, and HTML — not CSV files with mismatched column types.
It is already well-curated. These are not raw transactional logs or IoT sensor dumps. They are authored documents that went through review processes before they reached us.
It is considered authoritative. When a methodology document says "use FBDI for bulk imports," that is the standard. There is no "bronze version" that needs to be refined into a "gold version." The document is the gold.
The transformation is different. We are not cleaning column formats or deduplicating customer records. We are chunking text, generating embeddings, and extracting entities for an ontology. The pipeline is ingest → chunk → embed → index — not bronze → silver → gold.
When your source data is already authoritative and well-curated, a three-layer refinement pipeline is solving a problem you do not have.
Where I See Over-Rotation
I have been reviewing GenAI application architectures from multiple teams, and I see a recurring pattern: the Medallion Architecture applied reflexively, almost as if it were sacrosanct. Bronze layer for raw documents. Silver layer for "cleaned" documents. Gold layer for "ready" documents. Three copies of essentially the same data, with transformation logic between each layer that adds complexity, latency, and cost — but does not materially improve the data.
When I ask teams what the silver layer actually does, the answers are often vague: "It standardizes the format." Standardizes from what to what? The document was already a PDF. "It removes duplicates." Fair, but duplicate detection can be a single query with VECTOR_DISTANCE(), not an entire architectural layer. "It validates quality." How? The document was authored by a subject matter expert and reviewed before publication.
I am not arguing that data quality does not matter. It matters enormously. I am arguing that the Medallion pattern is not the only — or even the best — way to manage data quality in a GenAI knowledge base.
A Simpler Alternative
For the Digital Brain, we use a flat structure with status flags. Every document goes into a single table. A set of columns indicates its readiness and quality status. No data duplication, no multi-layer pipeline, no bronze-silver-gold ceremony.
-- Single table with status flags instead of medallion layers
CREATE TABLE documents ( doc_id NUMBER GENERATED ALWAYS AS IDENTITY
, title VARCHAR2(500)
, content CLOB
, namespace VARCHAR2(64)
, source_url VARCHAR2(1000)
-- Status flags replace medallion layers
, is_active NUMBER(1) DEFAULT 1 -- 1=live, 0=draft/archived
, is_chunked NUMBER(1) DEFAULT 0 -- has been chunked for RAG
, is_embedded NUMBER(1) DEFAULT 0 -- embeddings generated
, is_indexed NUMBER(1) DEFAULT 0, -- added to vector index
, quality_score NUMBER(3,2), -- automated quality check
, reviewed_by VARCHAR2(128), -- human reviewer (if applicable)
, review_date DATE
, ingested_at TIMESTAMP DEFAULT SYSTIMESTAMP
, updated_at TIMESTAMP );
-- Your RAG queries simply filter on the flags
SELECT doc_id, title, content
FROM documents
WHERE is_active = 1
AND is_embedded = 1
AND namespace = 'oracle.fusion'
;If a document is not ready for production, is_active = 0. It is still in the system — queryable for auditing and debugging — but excluded from RAG retrieval. When it is ready, flip the flag. No data migration from one layer to another. No pipeline to maintain between bronze and silver. No triple-storage cost.
Oracle Technical Note
Oracle 26ai's Deep Data Security can enforce these flags at the database kernel level. Define a policy that automatically filters is_active = 0 rows for the MCP service account. The AI agent literally cannot see inactive documents, regardless of what SQL it constructs. This provides the same data quality gate that Medallion's layer promotion gives you — but without the architectural overhead.
When Medallion Still Makes Sense
I want to be clear: the Medallion Architecture is not wrong. It is wrong for this use case. There are legitimate scenarios where medallion layers earn their keep:
Raw, messy source data. If you are ingesting transactional data, IoT feeds, or third-party data with inconsistent schemas, a progressive refinement pipeline is genuinely valuable.
Regulatory audit requirements. Some industries require an immutable record of data as received (bronze) and data as transformed (silver/gold). The layers serve as an audit trail.
Multiple consumers with different needs. If the data warehouse team wants aggregated gold tables while the data science team wants raw bronze data, the layers serve different audiences.
Complex transformation logic. When the transformation between raw and business-ready involves 50 rules, multiple lookups, and data enrichment from external sources, formalizing the stages makes the pipeline testable and debuggable.
Medallion Makes Sense When
Source data is raw, messy, or unstructured in a bad way
Heavy transformation needed (schema mapping, dedup, enrichment)
Multiple consumers need data at different stages
Regulatory audit requires immutable stage records
Data arrives from external systems you do not control
Flat + Flags Makes Sense When
Source data is authored, reviewed, and authoritative
Transformation is ingest → chunk → embed (not clean → conform)
Single primary consumer (RAG pipeline / MCP server)
Quality management is about readiness, not refinement
You control the content pipeline end to end
The Deeper Question
The real issue is not about Medallion versus flat tables. It is about whether we are choosing architectures based on the problem in front of us or based on the patterns we already know.
The Medallion Architecture is well-documented, well-tooled, and widely taught. It appears in Databricks training, in conference talks, in job descriptions. It has become a default — something architects reach for because it is familiar, not because the problem demands it. And defaults that are not questioned become dogma.
The best architecture is the simplest one that solves the problem you actually have — not the most sophisticated one that solves a problem you might have someday.
In the GenAI era, the data challenges are different. We are not cleaning up messy transactional data for BI dashboards. We are building knowledge systems from curated, authoritative content. The ingestion pipeline — chunk, embed, index, ontology-extract — looks nothing like the bronze-silver-gold pipeline that Medallion was designed for. When we force our data into that pattern, we add complexity that does not earn its keep.
A Note on Oracle ADW
Oracle Autonomous Data Warehouse supports both approaches seamlessly. If your workload genuinely needs Medallion, ADW handles it well — schema isolation, materialized views for layer transitions, and DBMS_CLOUD for external data loading. If your workload is better served by a flat structure with flags, ADW's partitioning, virtual columns, and Deep Data Security policies give you the same data quality controls without the multi-layer overhead. The database does not care about your architecture religion — it supports whatever the problem requires.
• • •
Practical Advice
If you are building a GenAI knowledge base — a RAG pipeline, a Digital Brain, an MCP-backed Knowledge Repository — ask yourself three questions before reaching for Medallion:
First: Is my source data messy, or is it already curated and authoritative? If it is authored content with editorial review, Medallion's refinement pipeline is solving a problem you do not have.
Second: What does my transformation pipeline actually do? If it is chunking, embedding, and indexing — not schema mapping and deduplication — the Medallion abstraction does not map to your workflow.
Third: Can I achieve the same data quality guarantees with a simpler mechanism? A status flag, a quality score column, a Deep Data Security policy that hides non-ready data from the AI agent — these are lighter-weight tools that often accomplish the same goal.
To Medallion or not to Medallion? The answer, as with most architecture decisions, is: it depends. But it should depend on the problem, not on the pattern. And for GenAI knowledge bases built on well-curated, authoritative content, the simpler answer is often the better one.